이미지 파일, 폴더를 직접 드래그하거나 Ctrl+V 단축키를 사용하여 클립보드의 스크린샷을 붙여넣으세요. JPG, PNG, WebP 형식의 자동 인식을 지원합니다.
이미지에서 문자를 즉시 추출하세요.
비공개, 안전, 완전 로컬화.
이미지 또는 폴더를 클릭하거나 여기로 드래그하여 업로드하세요
JPG, PNG, WebP 형식 지원
모든 처리는 브라우저 로컬에서 수행되며, 이미지와 데이터가 기기를 떠나지 않습니다.
WebAssembly 및 ONNX Runtime 기술을 기반으로 브라우저에서 네이티브에 가까운 성능을 제공합니다.
로드 후 인터넷 연결 없이 작동합니다. API 키가 필요 없으며 서버 비용이나 제한이 없습니다.
이미지 파일, 폴더를 직접 드래그하거나 Ctrl+V 단축키를 사용하여 클립보드의 스크린샷을 붙여넣으세요. JPG, PNG, WebP 형식의 자동 인식을 지원합니다.
강력한 딥러닝 모델이 내장되어 한국어, 중국어, 영어, 일본어 등 다국어를 지원하며 혼합 텍스트를 자동 인식하여 모든 문자를 정밀하게 추출합니다.
인식 결과가 실시간으로 표시되며, 텍스트를 클릭하면 원본 이미지의 위치를 확인할 수 있습니다. 온라인 편집 및 수정을 지원하여 출력 내용의 100% 정확성을 보장합니다.
인식이 완료되면 원클릭으로 클립보드에 복사하거나 TXT, Word 등 다양한 형식으로 내보낼 수 있어 문서 처리 효율을 크게 높여줍니다.
OOCCRR은 무료인가요?
내 이미지가 서버로 업로드되나요?
왜 OOCCRR의 인식 속도가 빠른가요?
어떤 언어의 문자 인식을 지원하나요?
이미지 일괄 인식을 지원하나요?
오프라인에서도 사용할 수 있나요?
인식 결과의 정확도는 어떤가요?
사용하려면 등록이나 로그인이 필요한가요?
단계별 튜토리얼
가져오기부터 내보내기까지 핵심 화면 상태를 차례대로 보고 같은 흐름을 바로 따라 할 수 있습니다.
표시된 모든 단계는 브라우저 안에서 로컬로 처리되며, 파일은 서버로 업로드되지 않습니다.
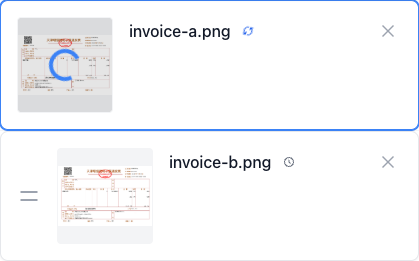
이미지 파일, 폴더를 직접 드래그하거나 Ctrl+V 단축키를 사용하여 클립보드의 스크린샷을 붙여넣으세요. JPG, PNG, WebP 형식의 자동 인식을 지원합니다.
강력한 딥러닝 모델이 내장되어 한국어, 중국어, 영어, 일본어 등 다국어를 지원하며 혼합 텍스트를 자동 인식하여 모든 문자를 정밀하게 추출합니다.
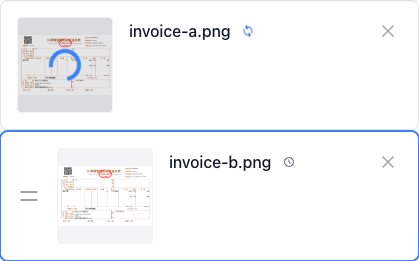
이미지 OCR는 브라우저 안에서 로컬로 처리되며, 이 단계에서 파일이 어떤 서버에도 업로드되지 않습니다.
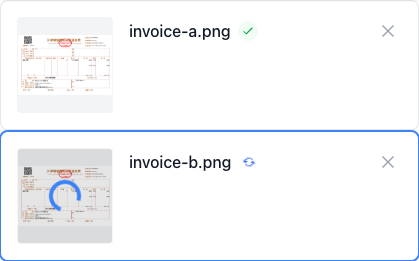
인식이 완료되면 원클릭으로 클립보드에 복사하거나 TXT, Word 등 다양한 형식으로 내보낼 수 있어 문서 처리 효율을 크게 높여줍니다.
