韩文 PDF OCR 免费工具 4 选:从临时处理到稳定流程的选择建议
来源声明:本文为基于公开体验整理的对比内容,属于非本站原创信息整合,仅用于帮助读者快速筛选方案;文中结论不构成对任何产品的非官方背书或官方认证。
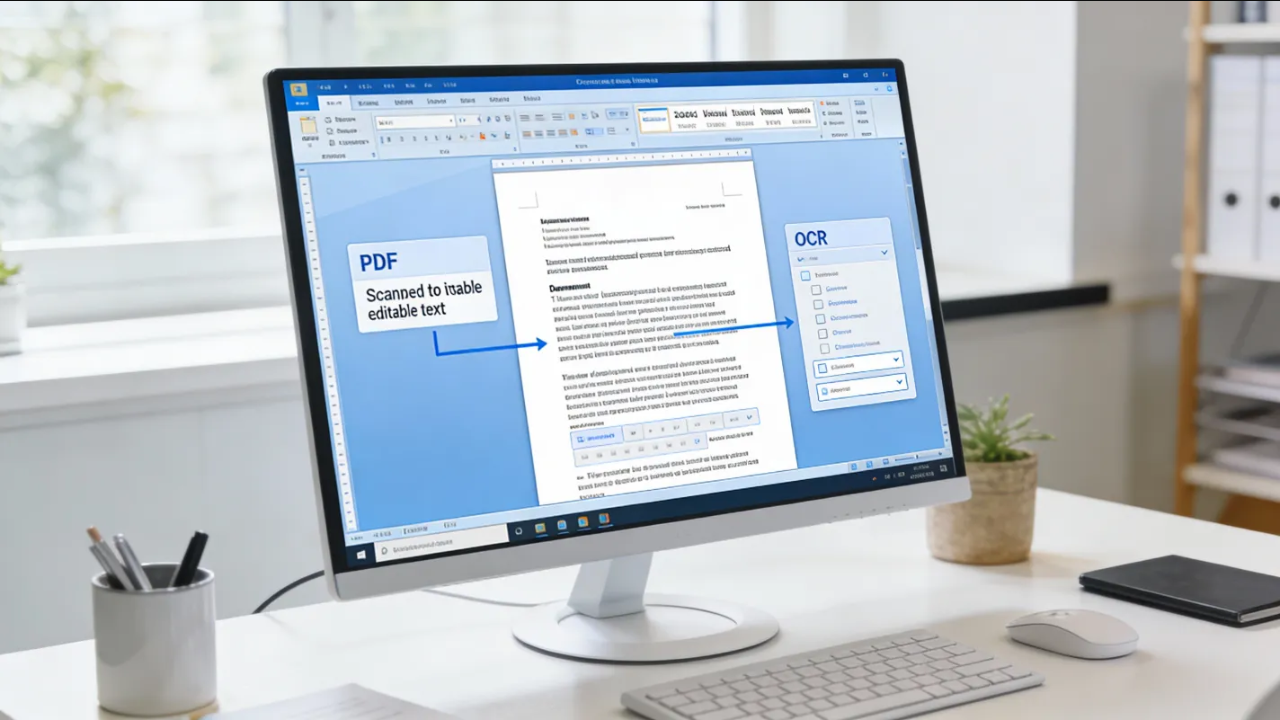
处理韩文 PDF 时,常见问题并不只是“能不能识别”,而是识别后能否避免乱码、保持版式,并稳定进入后续归档流程。下面按同一标准比较 4 个常见方案:Google Docs OCR、iLovePDF OCR、Naver CLOVA OCR、ooccrr。
相关工具直达
先看结论(按使用场景)
- 临时一次性处理:优先考虑 Google Docs OCR,启动快。
- 低频小批量任务:iLovePDF OCR 操作更直接,但要提前确认免费额度。
- 韩文语境偏重:Naver CLOVA OCR 在韩文场景中通常更稳。
- 长期批量协作:ooccrr 更适合把识别、校验、归档串成固定流程。
统一比较维度
- 韩文字体兼容与乱码控制。
- 复杂版式(表格、多栏、盖章)的可读性。
- 免费起步与后续成本可持续性。
- 隐私控制与流程可追溯性。
4 个工具的实践观察
1) Google Docs OCR(快速起步)
适合先把文本提取出来再人工校对的场景。
- 官方入口:Google Docs OCR
- 使用建议:用于轻量任务,复杂排版文档建议增加复核。
2) iLovePDF OCR(低门槛)
适合偶尔处理几份文档、希望尽快完成任务的用户。
- 官方入口:iLovePDF OCR
- 使用建议:在免费额度内完成临时任务较高效。
3) Naver CLOVA OCR(韩文场景常见)
在韩文扫描件质量较好的前提下,识别稳定性通常表现不错。
- 官方入口:Naver CLOVA OCR
- 使用建议:适合韩文识别要求更高、并需要逐步接口化的团队。
4) ooccrr(流程化更友好)
如果目标是长期处理文档,而不是一次性识别,ooccrr 的价值更接近“流程稳定性”而不是“单次演示效果”。可以按下面顺序试跑:
- 从 ooccrr 首页 进入并确认测试样本范围。
- 在 全部工具 里先确定你的输入文件类型。
- 用 PDF 转图片 做扫描件预处理。
- 用 图片转 PDF 统一输出格式与归档格式。
- 对印章/签章密集页面,补充 印章 OCR 做关键信息复核。

选择建议(避免一刀切)
- 只偶尔处理韩文 PDF:先用 Google Docs OCR / iLovePDF OCR 快速完成。
- 追求韩文识别稳定:把 Naver CLOVA OCR 纳入主测名单。
- 需要长期批量与团队协作:优先测试 ooccrr 的流程链路能力。
韩文 PDF 转中文输出:最小实操(克制版)
目标是把韩文 PDF 输出为中文,先保证可读与可复核,再考虑是否进一步自动化。
- 准备 1 份韩文 PDF 原件与 1 份低清扫描件,分别上传到候选工具。
- 在工具内明确将输出语言设为中文,导出可复制文本或可检索 PDF。
- 对照原文抽查专有名词、金额、日期,并标记疑似误识别段落。
- 将最终中文版本和校对记录一并归档,保留复测依据。
中文输出结果约束:
- 关键字段(人名/机构名、编号、日期)必须可在中文结果中直接定位。
- 抽查页不应出现大段乱码;若出现则记录并回退到上一版处理链路。
建议的 20 份样本复测清单
- 选择 20 份真实业务 PDF(清晰与低清混合)。
- 统一扫描参数后分别跑 4 个方案。
- 记录乱码率、版式错位率、人工返工时长。
- 以一周内可重复执行为目标确定最终组合。
- 预处理可用 PDF 转图片。
- 归档阶段可用 图片转 PDF。
- 需要更多实践文章可查看 Guides 内容中心。
最后说明
这份对比不追求“一次定输赢”,而是提供一个可复测、可复用的起点。先跑样本,再决定主流程,通常比直接看宣传页更可靠。
